TCP拥塞控制算法
基础知识
运作方式
TCP 使用多用拥塞控制策略来避免雪崩式拥塞。TCP会为每条连接维护一个“拥塞窗口”来限制可能在端对端间传输的未确认分组总数量。这类似于TCP流量控制机制中使用的滑动窗口。TCP在一个连接初始化或超时后使用一种“慢启动”机制来增加拥塞窗口的大小。其起始值一般为最大分段大小MSS的两倍,虽然名为“慢启动”,起始值也比较低,但其增长非常快:当每个分段得到确认之后,拥塞窗口就会增加一倍,使得每次往返时间(round-trip time,RTT)内拥塞窗口能高效地双倍地增长。
当拥塞窗口超过慢启动阈值(ssthresh)时,算法就会进入“拥塞避免”阶段。在拥塞避免阶段,只要未收到重复确认,拥塞窗口则在每次往返时间内线性增加一个MSS大小。
拥塞窗口
在TCP中,拥塞窗口(congestion window)是任何时刻内确定能被发送出去的字节数的控制因素之一,是阻止发送方至接收方之间的链路变得拥塞的手段。他是由发送方维护,通过估计链路的拥塞程度计算出来的,与由接收方维护的接收窗口大小并不冲突。
当一条连接创建后,每个主机独立维护一个拥塞窗口并设置值为连接所能承受的MSS的最小倍数,之后的变化依靠线增积减机制来控制,这意味如果所有分段到达接收方和确认包准时地回到发送方,拥塞窗口会增加一定数量。该窗口会保持指数增大,直到发生超时或者超过一个称为“慢启动阈值(ssthresh)”的限值。如果发送方到达这个阈值时,每收到一个新确认包,拥塞窗口只按照线性速度增加自身值的倒数。
当发生超时的时候,慢启动阈值降为超时前拥塞窗口的一半大小、拥塞窗口会降为1个MSS(Tahoe算法,其他算法略有不同),并且重新回到慢启动阶段。
在流量控制中,接收方通过TCP的“窗口”值(Window Size)来告知发送方,由发送方通过对拥塞窗口和接收窗口的大小比较,来确定任何时刻内需要传输的数据量。
和式增加,积式减少
和式增加,积式减少(additive-increase/multiplicative-decrease,AIMD,这里简称“线增积减”)是一种反馈控制算法,其包含了对拥塞窗口线性增加,和当发生拥塞时对窗口积式减少。多个使用AIMD控制的TCP流最终会收敛到对线路的等量竞争使用。
Tahoe 算法
Tahoe 算法主要有三个机制来控制数据流和拥塞窗口
- 慢启动 slow start(SS)
- 拥塞避免 congestion avoidance(CA)
- 快速重传 fast retransimit(FS)
慢启动阶段:初始设置拥塞窗口值为1,2,4或10个 MSS。拥塞窗口在每接收到一个确认包时增加,每个RTT内成倍增加,。发送速率随着慢启动的增加而进行,直到遇到出现丢失、达到慢启动阈值、或者接收方的接收窗口进行限制。如果发生丢失,则TCP推断网络出现了拥塞,会试图采取措施来降低网络负载。
在处理报文丢失的事件上,Tahoe 算法会进入“快速重传”阶段,慢启动阈值设为之前拥塞窗口值的一半,拥塞窗口值降为初始值,重新进入慢启动阶段。当拥塞窗口值达到慢启动阈值时,每RTT内拥塞窗口增加值则为“MSS除以CWND”的值,所以拥塞窗口按线性速度增加。

Reno 算法
Tahoe 算法在遇到报文丢失之后的反应过于保守,直接进入慢启动阶段。Reno 算法实现了一个名为“快速恢复”的机制,慢启动阈值设为之前拥塞窗口值的一半,和作为新的拥塞窗口值,并跳过慢启动阶段,直接进入拥塞控制阶段。
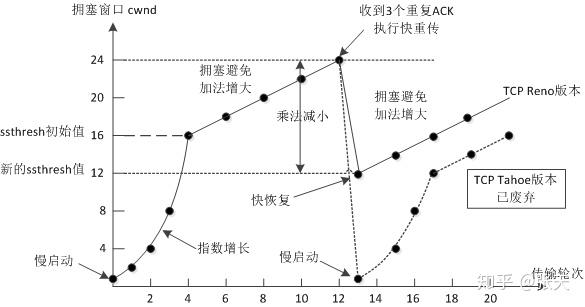 图1. Tahoe VS Reno
图1. Tahoe VS Reno
cubic 算法
在现今网络带宽朝着速度更快,距离更长的趋势发展。传统网络拥塞算法中性能不够优越,BDP(bandwidth and delay product,代表带宽被完全利用时网络能容纳的数据总量包)不高。主要是因为在进入拥塞避免阶段之后,拥塞窗口每经过一个RTT才加1,拥塞窗口增长速度太慢,当遇到高带宽环境时,要经过很多 RTT ,拥塞窗口才能接近于一个BDP。如果数据流很短,那么拥塞窗口没有达到BDP之前,数据流就已经结束了。
CUBIC的窗口增长是一个三次函数,启动更快,经过一段时间稳定的数据传输之后,也可以更快的找到新的拥塞窗口值。
在遇到数据丢失的情况时,CUBIC 会通过乘以因子 β (0,1)来降低拥塞窗口。

BBR 算法
上面的算法中,有一个假设就是“丢包的发生意味着网络的拥塞”。而在无线环境中,电磁波受到干扰的情况会大大的增加,丢包并不意味着网络负载已经达到了最大。
BBR算法,致力于解决两个问题:
- 在有一定丢包率的网络链路上充分利用带宽
- 降低网络链路上的buffer占用率,从而降低延迟。
而且,丢包的发生不只有拥塞的丢包,还有错误的丢包。而基于丢包的TCP拥塞控制算法不能区分拥塞丢包 和 错误丢包。
而错误丢包率则在不同网络下大有不同,在数据中心延迟一般为10-100微妙,带宽10-40微妙,带宽为10-40 Gbps,乘起来得到的发送窗口(BDP)为12.5KB 到 500KB。而在广域网中,带宽可能是100Mbps,延迟为100毫秒,乘起来的发送窗口为10MB。丢包错误率一般跟发送窗口的平方成反比,这样,广域网的发送窗口比数据中心高一到两个数量级,这样其错误丢包率要低2-4个数量级才能正确工作。因此标准TCP在有一定错误丢标率的长肥管道上只会收敛到一个很小的发送窗口。
其次网络中会有一些 buffer 造成缓冲区膨胀的问题。
BBR 算法通过以下两点解决问题:
- 既然区分不了拥塞丢包和错误丢包,那么索性就不再考虑丢包。
- 既然灌满数据数据管道的方式容易造成缓冲区膨胀,那么 BBR 就直接分别估计带宽和延时,而不是直接估计水管的容积。
但是也有一种观点认为,BBR 算法在有一定丢包率的情况下,抢占了更多的公网带宽,有一种不道德的感觉。但我认为,当所有人都使用更先进的拥塞控制算法时,网络的资源利用率一定会大大提升。 关于 BBR 算法的详解,可以看我下一篇博客。
- Author: kunpeng
- Link: https://kunpengdai.github.io/post/2019/TCP%E6%8B%A5%E5%A1%9E%E6%8E%A7%E5%88%B6%E7%AE%97%E6%B3%95/
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.