Redis 数据结构
数据结构
SDS/simple dynamic strings
|
|
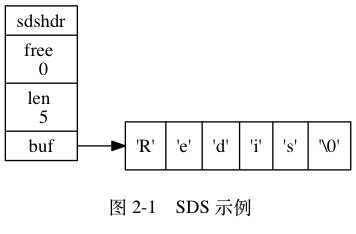
SDS遵循C语言的规则,在字符串末尾添加了’\0’,这样就可以直接使用C字符串函数库中的函数。
SDS保存了字符串的长度,这样可以在常数时间内获取字符串的长度。
SDS在字符串扩展时可以自动扩展申请的字符串长度,这样可以避免发生缓冲区溢出的可能性。
SDS中存在着free空间【空间预分配和惰性删除】,可以尽量减少内存的重分配。
SDS也是二进制安全的,因此也可以用来保存二进制数据。
| C字符串 | SDS |
|---|---|
| 获取字符串长度的复杂度为O(N) | 获取字符串长度的复杂度为O(1) |
| API是不安全的,可能会造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N此内存分配 | 修改字符串长度N次至多执行N次内存分配 |
| 只能保存文本数据 | 可以保存文本或者二进制数据 |
| 可以使用所有<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
链表
|
|
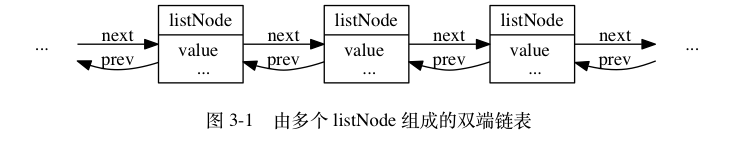
虽然使用多个listNode结构就可以组成链表,但是使用adlist.h/list 来持有链表的话,操作起来会更加方便。
|
|
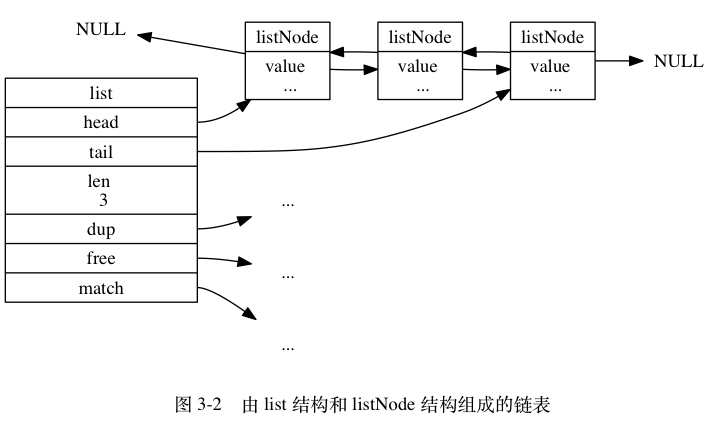
redis链表实现了如下的特性:
- 双端:链表节点带有prev和next指针,获取某个节点的前置节点和后置节点的复杂度都是O(1)
- 无环:表头节点的prev指针和表尾节点的next指针都指向NIULL,对链表的访问以NULL为终点
- 带表头指针和表尾指针:通过list结果的head和tail指针,程序获取链表头结点和尾节点的复杂度为O(1)
- 带链表长度计数器:程序使用list结构的len属性来对list持有的链表节点进行计数,程序获取链表中节点数量的复杂度为O(1)
- 多态:链表节点使用void*指针来保存节点值,并且可以通过list结构的dup、free、match三个属性为节点值设置类型特定函数,所以链表可以保存各种不同类型的值。
redis队列主要可以用来做消息队列,发布订阅pub/sub,列表键,慢查询,监视器等。做消息队列的话,由于没有实现ack机制,且在宕机时可能会有部分数据没有持久化,对数据可靠性要求较高的场景不适合使用redis list来做消息队列。
字典
redis字典使用的哈希表由 dictht结构定义:
|
|
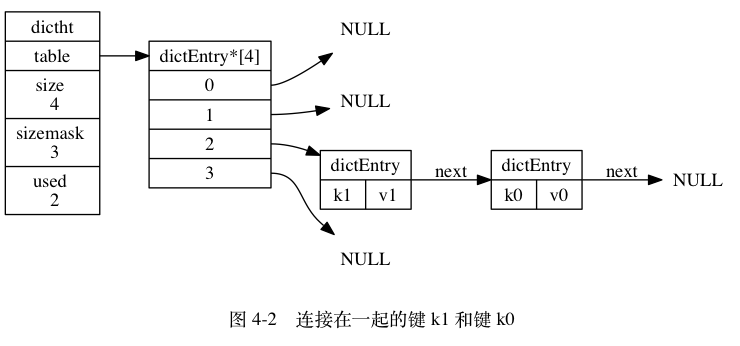
table 属性是一个数组, 数组中的每个元素都是一个指向 dict.h/dictEntry 结构的指针, 每个 dictEntry 结构保存着一个键值对。
size 属性记录了哈希表的大小, 也即是 table 数组的大小, 而 used 属性则记录了哈希表目前已有节点(键值对)的数量。
sizemask 属性的值总是等于 size - 1 , 这个属性和哈希值一起决定一个键应该被放到 table 数组的哪个索引上面。

哈希表节点使用 dictEntry 结构表示, 每个 dictEntry 结构都保存着一个键值对:
|
|
key 属性保存着键值对中的键, 而 v 属性则保存着键值对中的值, 其中键值对的值可以是一个指针, 或者是一个 uint64_t 整数, 又或者是一个 int64_t 整数。
next 属性是指向另一个哈希表节点的指针, 这个指针可以将多个哈希值相同的键值对连接在一次, 以此来解决键冲突(collision)的问题。
而字典的结构如下:
|
|
rehash
随着操作的不断执行, 哈希表保存的键值对会逐渐地增多或者减少, 为了让哈希表的负载因子(load factor)维持在一个合理的范围之内, 当哈希表保存的键值对数量太多或者太少时, 程序需要对哈希表的大小进行相应的扩展或者收缩。
扩展和收缩哈希表的工作可以通过执行 rehash 【渐进式】(重新散列)操作来完成, Redis 对字典的哈希表执行 rehash 的步骤如下:
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
跳跃表
跳跃表用来实现 zset,跳跃表【zskiplist】主要有以下几个属性:
header:指向跳跃表的表头节点。tail:指向跳跃表的表尾节点。level:记录目前跳跃表内,层数最大的那个节点的层数(表头节点的层数不计算在内)。length:记录跳跃表的长度,也即是,跳跃表目前包含节点的数量(表头节点不计算在内)。
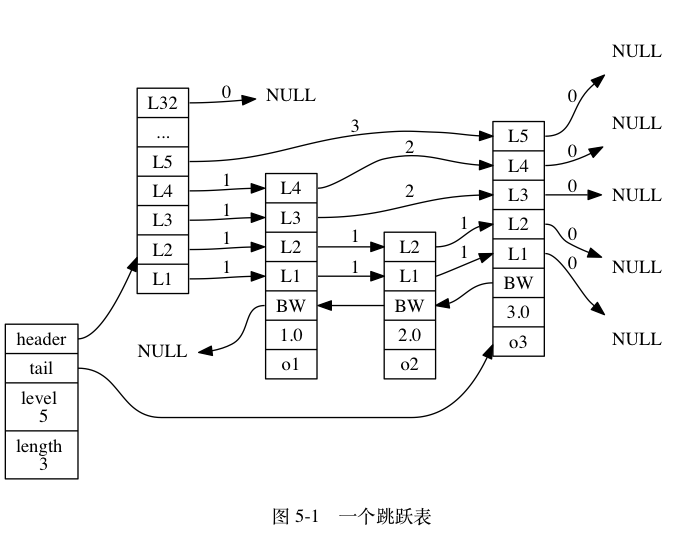
zskiplist结构hea的和tail指向的是 zskiplistNode结构,该结构包含以下属性:
- 层(level):节点中用
L1、L2、L3等字样标记节点的各个层,L1代表第一层,L2代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其他节点,而跨度则记录了前进指针所指向节点和当前节点的距离。在上面的图片中,连线上带有数字的箭头就代表前进指针,而那个数字就是跨度。当程序从表头向表尾进行遍历时,访问会沿着层的前进指针进行。 - 后退(backward)指针:节点中用
BW字样标记节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。 - 分值(score):各个节点中的
1.0、2.0和3.0是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。 - 成员对象(obj):各个节点中的
o1、o2和o3是节点所保存的成员对象。
总结:
- 跳跃表是有序集合的底层实现之一, 除此之外它在 Redis 中没有其他应用。
- Redis 的跳跃表实现由
zskiplist和zskiplistNode两个结构组成, 其中zskiplist用于保存跳跃表信息(比如表头节点、表尾节点、长度), 而zskiplistNode则用于表示跳跃表节点。 - 每个跳跃表节点的层高都是
1至32之间的随机数。 - 在同一个跳跃表中, 多个节点可以包含相同的分值, 但每个节点的成员对象必须是唯一的。
- 跳跃表中的节点按照分值大小进行排序, 当分值相同时, 节点按照成员对象的大小进行排序。
- Author: kunpeng
- Link: https://kunpengdai.github.io/post/2019/redis%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
- License: This work is under a 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议. Kindly fulfill the requirements of the aforementioned License when adapting or creating a derivative of this work.